A Dataset Sample
This Figure shows an example image conveying satire. The irony in the image is that the person is messaging someone a very heartfelt message on the mobile, while sitting on a toilet seat!

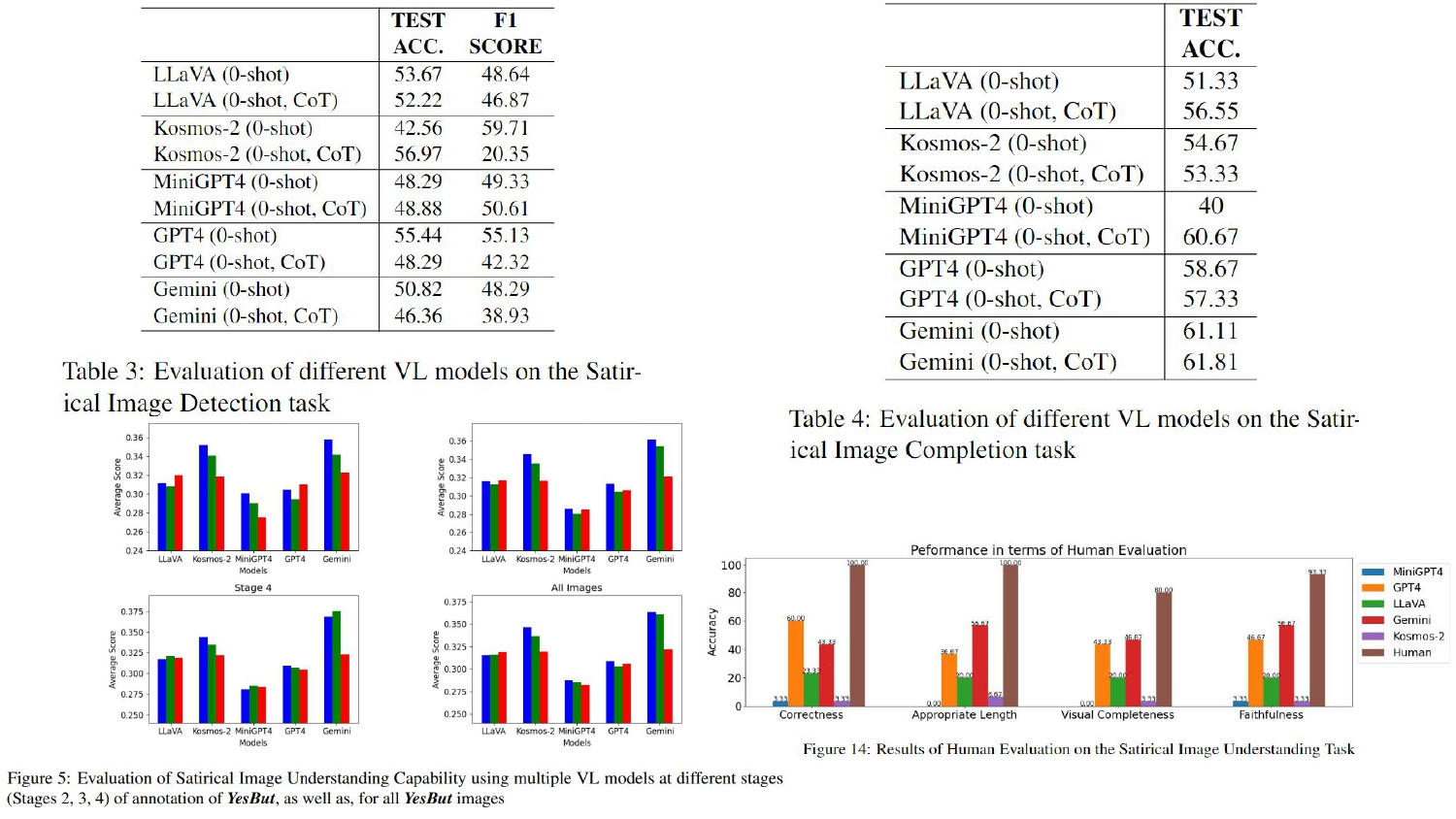
YesBut Dataset Curation
Our annotation Pipeline for YesBut in 4 Stages- (1) Collecting Satirical Images from Social Media (2) Human Annotation of satirical images (3) Generating 2D stick images using DALL-E 3 and annotated descriptions (4) Generating 3D stick images using DALL-E 3 and annotated descriptions
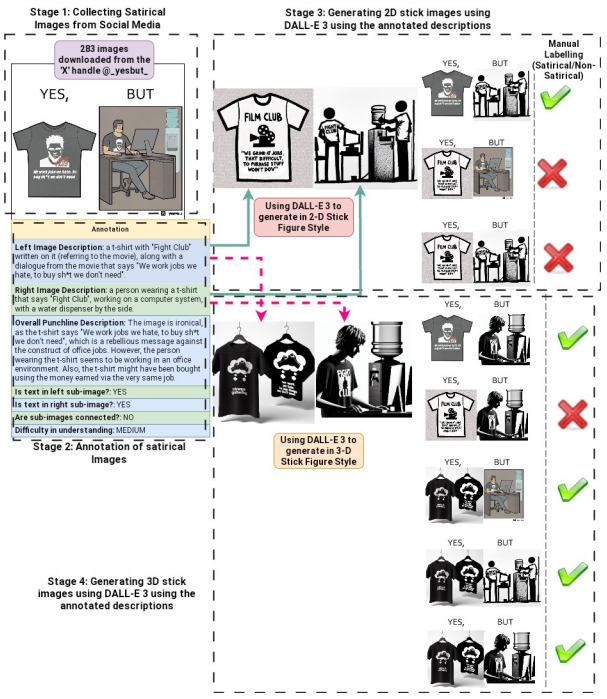
Distribution of the YesBut Dataset
Distribution of the original 283 satirical images downloaded from Social Media based on different aspects of image content and annotated descriptions
Task - Satirical Image Detection
This is a binary classification task, where given an image, the model needs to predict whether the image is satirical or not.

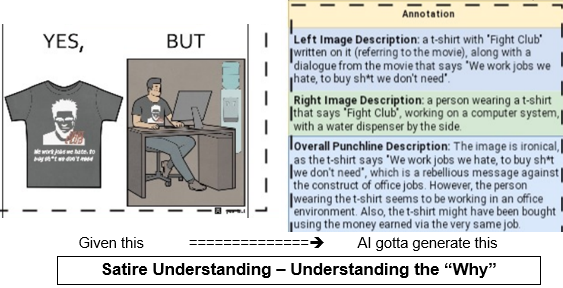
Task - Satirical Image Understanding
Given a satirical image, we evaluate the model’s satire understanding capability in images by (1) prompting the model to generate a textual description of each subimage as input, using the prompt “Describe the image”. (2) prompting the model to generate the punchline in the image using the following prompt (referred to as “WHYFUNNY_PROMPT” hereafter)- “Why is this image funny/satirical?”.
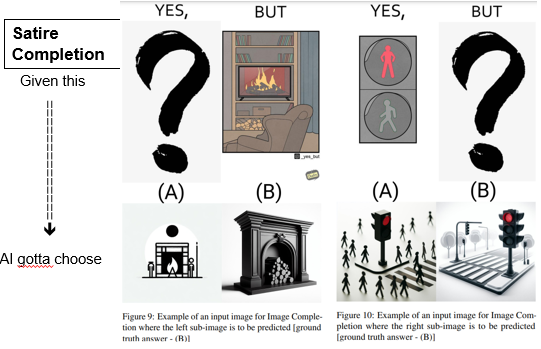
Task - Satirical Image Completion
Given either the left or right sub-image having the style of a colorized sketch, the other sub-image needs to be chosen from two options, one having a 2D, and the other having a 3D stick figure style, such that the entire image so formed is meaningful and satirical.
Results